
测试网经过 200K+ 数据集和 1,500TB 数据的严格验证。
Kite AI 已与全球顶尖的 AI 领域合作伙伴建立了合作网络,包括 AVAX、Near、伯克利大学、Sui 和 Polygon Labs 等。
让我们一起来详细了解 Kite AI 首个“归因智能证明”
1. 引言
近年来,深度学习和机器学习的快速发展推动了各个行业的变革,从医疗健康到金融领域,人工智能(AI)已成为技术创新的核心。
尽管取得了显著进展,AI 的发展仍然主要由少数资金雄厚、集中的实体主导,这些实体通常控制着数据、计算资源和专有模型的访问。这种局面引发了关于 AI 系统中的价值公平分配、数据所有权以及激励机制广泛对齐的根本性问题。
Kite AI 的使命便是要改变这一现状。
在这种背景下,Kite AI 作为一个专为去中心化 AI 研究和应用而设计的区块链解决方案应运而生。通过采用“归因智能证明”(Proof of AI),Kite AI 致力于为 AI 数据、模型开发和 AI 驱动的代理提供一个透明、安全且公平的协调层。
Kite AI 已与 AVAX 合作推出了首个 AI 专注的 Layer 1 主权区块链。
通过利用 Avalanche 的高性能、可扩展的基础设施,Kite AI 确保:
- 利用 Avalanche 的子网和共识效率,实现快速的 AI 计算。
- 无瓶颈地无缝扩展以支持 AI 工作负载。
- 为 AI 研究和模型部署提供去中心化、无需许可的基础。
Kite AI 测试网链接:https://testnet.gokite.ai/

2. 背景与动机
2.1 集中式 AI 生态系统
传统的 AI 开发流程严重依赖于集中化的数据仓库和集中式计算资源。主导性的 AI 平台通常利用大量数据集,这些数据集来自公共和私人渠道,但并未充分奖励原始数据提供者。因此,数据贡献者和模型开发者通常在不平衡的权力结构中运作,往往无法获得足够的认可或补偿。
此外,AI 领域中的封闭治理机制限制了透明性,阻碍了可重复性,并可能导致垄断的形成。集中化治理削弱了开放创新,限制了合作机会,并增加了偏见或不当模型使用的风险。
2.2 现有区块链解决方案
为应对这一问题,已有一些基于区块链的框架试图去中心化 AI 和数据市场。传统的共识机制,如工作量证明(PoW)或权益证明(PoS),在某些加密货币和 DeFi 应用中已证明有效。然而,这些机制通常未能解决以下问题:
- 细粒度归因:需要根据数据提供者、模型开发者、AI 代理等的边际贡献来奖励个体贡献者。
- 定制化治理:需要适合 AI 任务的专门环境,包括大规模数据索引和链上 / 链下计算。
- AI 激励机制:先进的博弈论模型可防止数据剽窃、模型盗窃或在训练流程中的恶意贡献。
2.3 需要专门构建的基础设施
通用区块链协议缺乏处理 AI 开发和商业化复杂性的专门功能。这些限制包括吞吐量不足,无法存储或引用大规模数据集,以及在多层次 AI 工作流中进行价值归因的困难。Kite AI 的提案——一个兼容 EVM 的 Layer 1 区块链,通过 PoAI 增强——旨在填补这些空白,推动一个建立在公平、透明和包容性基础上的全新 AI 经济。
3. Kite AI 架构
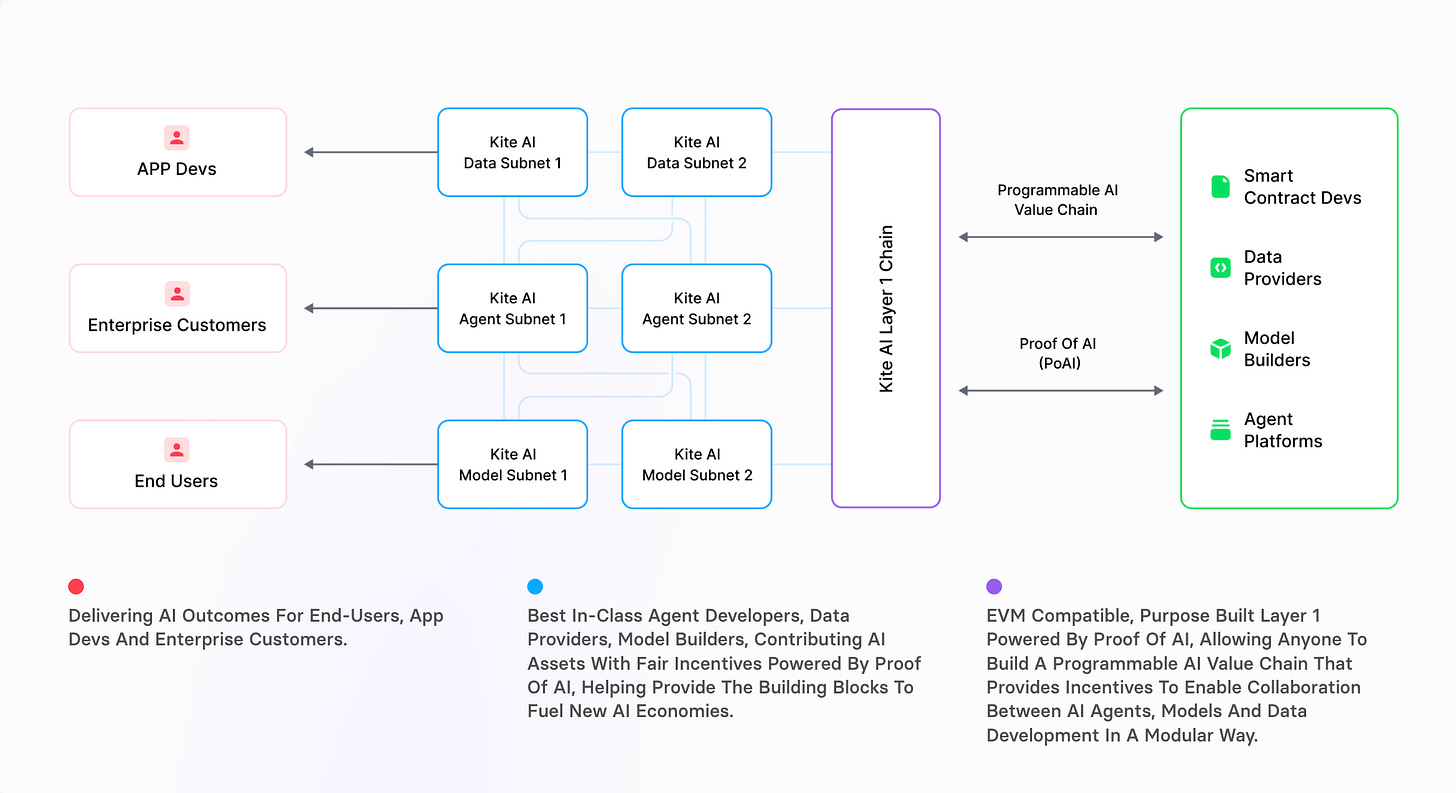
Kite AI 推出了一种全新的 Layer 1 区块链,专为 AI 集成了四个关键组件:
- 归因智能证明(Proof of AI)
- 去中心化数据访问引擎
- 可组合的 AI 生态系统与可定制子网
- 去中心化、可移植的 AI 记忆
3.1 归因智能证明(Proof of AI)
归因智能证明是 Kite AI 的核心共识机制。与主要侧重于计算难题或抵押担保的工作量证明(PoW)或权益证明(PoS)不同,Proof of AI 旨在衡量和奖励对 AI 资产的真实贡献:
- 数据贡献:数据提供者根据数据质量、相关性以及对模型性能的改进等指标获得奖励。
- 模型开发:开发者根据模型的准确性、效率或用户接受度获得报酬。
- 代理效用:AI 代理(如聊天机器人、自动交易代理)根据其服务使用情况、可靠性和用户满意度获得奖励。
Proof of AI 通过结合数据估值技术(如受 Shapley 值启发的方法)和链上治理,动态评估每个贡献如何影响整体 AI 经济。这建立了一个反馈回路,激励有意义的输入,抑制恶意或冗余活动。
归因智能证明融入了先进的博弈论机制,以预防理性和非理性的攻击:
- 理性攻击:那些试图在没有实际贡献的情况下最大化奖励的行为,会被通过边际贡献评分来阻止。
- 非理性攻击:如数据污染或模型破坏等恶意行为,会通过链上检测被识别并处罚,从而确保系统的稳定性。
3.2 去中心化数据访问引擎
Kite AI 的去中心化数据访问引擎提供无许可但安全的数据检索和存储接口。该引擎支持:
- 高量数据管理:通过一个优化的分布式节点网络来支持 AI 相关任务,确保大规模数据能够被访问和索引。
- 内建归因:智能合约将数据使用与具体贡献者关联,自动根据 Proof of AI 分配奖励。
- 货币化机会:数据提供者可以设置定价方案或使用条件,控制数据使用的时机和方式。
3.3 可组合的 AI 生态系统与可定制子网
Kite AI 支持可定制子网——在 Layer 1 架构中专门为不同 AI 工作负载而设立的区域:
- 治理灵活性:每个子网可以实施独特的治理规则、代币经济模型或共识参数,以适应特定用例。
- 模块化基础设施:开发者可以通过整合聚焦数据策划、模型训练或代理部署的子网来组合多模式 AI 工作流。
- 隔离与安全性:一个子网中的故障不会影响其他部分的网络,增强了整体的稳定性。
3.4 去中心化、可移植的 AI 记忆
AI 模型通常需要持久存储学习到的参数以及与交互相关的记忆。Kite AI 的去中心化、可移植的 AI 记忆提供:
- 隐私保护:敏感的模型参数可以加密,确保即使在分布式环境中,知识产权也能得到保护。
- 长期模型溯源:模型所有权和版本历史将被记录在链上,确保透明性和可重复性。
- 可扩展性能:支持数十亿次交互,内建跟踪和归因机制,用于记录每次模型更新或推理。
4. 分析评估
4.1 公平归因
通过利用 Proof of AI,Kite AI 能够按贡献的影响比例分配奖励。Shapley 值或其他基于联盟的分配框架已集成到共识逻辑中,允许:
- 精细的数据贡献评分:评估每个数据子集对模型性能的影响。
- 透明的模型评估:链上审计模型训练过程,验证模型在准确性或效用上的真实改进。
- 代理监控:跟踪代理的使用情况,并将消费者支付或链上交易与特定代理输出相关联。
Proof of AI 专注于边际贡献,培养了一个系统性奖励质量而非数量的机制,减少了搭便车问题,降低了重复或低价值贡献的发生。
4.2 可扩展性和吞吐量
AI 工作流的需求,特别是涉及大规模数据集时,为区块链带来了独特的可扩展性挑战。Kite AI 通过以下方式解决这一问题:
- 部署子网:将任务和资源划分为专门的区域,减少了拥塞,并支持并行计算。
- 分层架构:将复杂计算卸载到特定子网的验证者或预言机,链上交易则记录关键元数据以便归因和奖励分配。
该架构促进了水平扩展,独立子网可以根据需求进行扩展。尽管如此,实际吞吐量仍取决于节点基础设施、带宽和子网内部的治理决策。
4.3 治理与安全
通过 Proof of AI 的检测与驱逐恶意行为者来维持安全,而治理则委托给子网级别的权力机构和代币持有者:
- 利益相关者对齐:子网治理代币确保了那些投入资源或专业知识的人能够参与决策。
- 跨子网协调:Layer 1 级别的共识规则统一了子网,防止了碎片化或不兼容协议的出现。
- 抗攻击性:Proof of AI 的激励机制设计降低了对 Sybil 攻击和数据污染的敏感度,通过根据实际效用动态加权贡献来减少这些威胁。
基于 Proof of AI 的治理比传统的 PoS 框架更好地对齐了利益相关者的激励,尽管新兴的威胁(如高级数据污染策略)仍需持续监控和更新检测算法。
5. 使用案例与潜在影响
5.1 数据市场
Kite AI 的去中心化数据引擎提供了一个安全、透明的数据交易平台。数据所有者可以放心地分享数据集——从医疗影像到自动驾驶日志——知道他们将得到补偿,并且能够控制自己的资产。
5.2 协作模型训练
AI 研究小组和企业可以利用 Kite AI 的子网共同开发模型。模型的改进将被链上跟踪,并且每个贡献者在超参数调优、数据清理或微调中的努力将得到直接的归因和补偿。
5.3 去中心化代理生态系统
在内容审核或金融预测等任务中运行的 AI 代理可以在子网内部署,并通过智能合约与最终用户互动。Proof of AI 确保了每个代理的效用和性能都能得到透明的衡量,从而简化了报酬机制并促进了跨代理的合作。
6. 结论
Kite AI 的设计理念承认了 AI 管道的复杂性,并通过多层次激励机制鼓励高质量的贡献,抑制恶意行为。然而,仍然存在一些开放问题,包括:
- 采纳与网络效应:任何基于区块链的生态系统的成功都依赖于关键质量的聚集。加速采纳可能需要通过战略伙伴关系和激励措施来吸引数据提供者和开发者。
- 归因的复杂性:虽然 PoAI 引入了先进的估值方法,但现实中的 AI 管道往往是动态和非线性的,归因框架仍需不断完善。
- 监管考虑:隐私法和知识产权法因地区而异,可能影响数据和模型所有权在链上的执行方式。
通过迭代改进和强有力的治理模型来解决这些挑战,将对 Kite AI 的长期成功至关重要。
文章声明:以上内容(如有图片或视频亦包括在内)除非注明,否则均为谈天说币原创文章,转载或复制请以超链接形式并注明出处。